 R을 활용한 요인 분석(인자분석, Factor Analysis) 정리 :: Data 쿡북
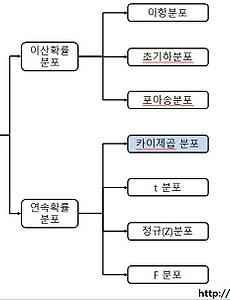
요인분석(인자분석, Factor Analysis)에 대해 조사하고 실습한 내용들을 정리한다. | 요인분석이란여러개의 서로 관련이 있는 변수들로 측정된 자료에서 그 변수들을 설명할 수 있는 새로운 공통변수를 파악하는 통계적 분석방법이다.예를 들면, 학생들 100명을 대상으로 국어,영어,수학,일반사회,지리, 역사, 물리, 화학, 생물 등 9개의 시험을 실시하여 성적을 구하였을 때 9개가 아닌 공통적으로 설명할 수 있는 공통인자(변수)를 파악하는 것이다즉, 국어, 영어를 언어능력수학, 물리를 수리능력등으로 분리해 내는 것이다. | 주성분분석(PCA)와 공통점과 차이점주성분 분석과 요인분석은 유사하지만 다른 특성을 갖고 있다.R을 활용한 주성분 분석은 이전 포스팅을 참고 바란다. (▶ http://datacoo..
2017. 3. 17.
R을 활용한 요인 분석(인자분석, Factor Analysis) 정리 :: Data 쿡북
요인분석(인자분석, Factor Analysis)에 대해 조사하고 실습한 내용들을 정리한다. | 요인분석이란여러개의 서로 관련이 있는 변수들로 측정된 자료에서 그 변수들을 설명할 수 있는 새로운 공통변수를 파악하는 통계적 분석방법이다.예를 들면, 학생들 100명을 대상으로 국어,영어,수학,일반사회,지리, 역사, 물리, 화학, 생물 등 9개의 시험을 실시하여 성적을 구하였을 때 9개가 아닌 공통적으로 설명할 수 있는 공통인자(변수)를 파악하는 것이다즉, 국어, 영어를 언어능력수학, 물리를 수리능력등으로 분리해 내는 것이다. | 주성분분석(PCA)와 공통점과 차이점주성분 분석과 요인분석은 유사하지만 다른 특성을 갖고 있다.R을 활용한 주성분 분석은 이전 포스팅을 참고 바란다. (▶ http://datacoo..
2017. 3. 17.